안녕하세요, 산격동 너구리입니다.
이번 포스팅은 SAS를 이용한 "복합표본 평균차이 검정"입니다. 복합표본이라는 단어가 붙었다고해서 너무 어렵게 생각하실 필요 없습니다. 계산은 우리가 직접하지 않습니다. 우리는 그저, 프로그램에게 정확한 명령을 내려주면 됩니다. 오늘 할 내용은, 복합표본에서 두 집단의 평균을 비교하는 예제를 실습해보겠습니다. T검정의 복합표본 버젼이라고 보시면 됩니다. T검정은 집단 간 평균 차이를 검정한다는 큰 중심을 잘 잡고 계시다면 그리 어렵지 않습니다. 바로 시작해보겠습니다.
개요
복합표본 평균차이 검정이란?
분석지침서에서 복합표본 회귀분석을 이용해서 평균을 비교한다고 나와있습니다. 회귀분석에 관한 내용이 나와도 당황하지 마시길 바랍니다!
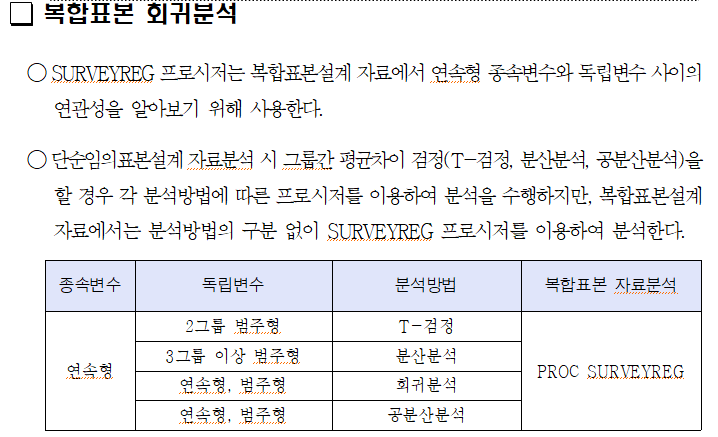
가정
분석지침서에서는 가정을 확인하는 과정이 생략되어 있습니다. 복합표본 자료분석에서는 가정에 대해 어떻게 처리를 하는 것인지 확인하기 위해서 국건영 통계팀에 전화 문의를 해보았는데요. 우선, 설문조사 자료이기 때문에 아마 가정을 충족시키지 않는 경우가 많을거라고 말씀해주셨고, 연구자에 따라 가정을 확인하고자 한다면 복합표본이라고 생각하지 말고, 일반적인 방법으로 가정을 확인해주면 된다고 대답해주셨습니다. 다른 포스팅에서 분석의 가정을 확인하는 작업을 해왔기 때문에 본 포스팅에서는 가정을 추가적으로 확인하지 않겠습니다.
예제

예제는 분석지침서에서 제공하는 상황과 동일하게 두었습니다. 하지만, 데이터 연도가 다르기 때문에 지침서의 결과와는 차이가 있을겁니다. 분석지침서와 동일한 과정을 밟으면서 하나씩 진행해보겠습니다.
데이터 불러오기
가장 먼저, 데이터를 불러와야합니다.


집단 변수 설정
복합표본 자료를 분석할 때에는 특정 관측치를 삭제하거나 일부만 사용하여 분석하면 안 됩니다. 따라서, 전체 데이터를 전부 사용하면서 내가 원하는 집단에 대한 결과를 얻기 위해서는 해당 집단을 구분할 수 있는 집단 변수를 추가해주어야합니다.

현재 예제에서의 목표는, "30세 이상에서 성별에 따른 수축기 혈압의 평균이 차이가 있는지" 확인하는 것입니다. 따라서, 우리의 관심 집단은 "30세 이상인 사람"을 의미합니다. 그렇기 때문에 관심 집단과 관심 집단이 아닌 대상을 구분하기 위해 "age30"이라는 새로운 변수를 추가하였으며 age가 30이상이라면 1, 그것이 아니라면 0인 값을 가지도록 설정하였습니다.

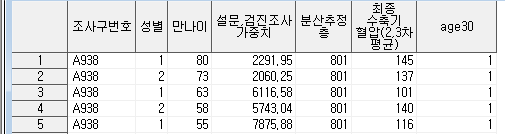
변수를 추가한 데이터는 아래와 같습니다. 5개의 관측치에 대해 모두 만나이가 30이상이므로 age30의 값이 전부 1인 것을 확인할 수 있습니다.
또한, 아래처럼 관심 집단에 대한 관측치 개수와 결측치 개수를 확인할 수 있습니다. 분석을 하면서 데이터를 살펴보는 습관을 들이시면 확실히 도움이 됩니다. 방향을 설정하고 분석을 하는 경우에는 데이터를 훑어보는 과정을 소홀히 하게 되는 경우가 많습니다. 데이터를 제대로 보지 않는다고 해서 분석이 항상 잘못된다고 할 수는 없지만, 데이터를 천천히 훑어보다보면 새로운 아이디어가 떠오를 수도 있고, 데이터의 결함을 발견할 수 있는 기회가 생깁니다!

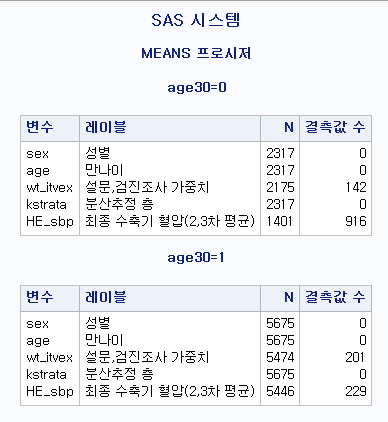
여기서 age30 = 0인 것은 우리의 관심 집단이 아니며, age30 = 1인 것이 우리의 관심 집단인 나이가 30세 이상인 집단입니다.
가설
귀무가설 : 만 30세 이상에서 성별에 따른 수축기 혈압의 평균은 차이가 없다.
대립가설 : 만 30세 이상에서 성별에 따른 수축기 혈압의 평균은 차이가 있다.
복합표본 평균 비교
이제 마지막인 분석 과정입니다. 복합표본에서의 평균비교는 Proc SurveyReg 문을 사용합니다. 이름에서 유추할 수 있듯이 회귀분석을 기반으로 분석합니다. T검정을 회귀분석으로 대체한다?? 조금 어색하실 수도 있는데, 회귀분석에 사용되는 독립 변수를 범주가 2개인 독립 변수만 넣는다고 생각하시면 조금 편할 수 있습니다. 이 부분은 Dummy Variable에 대한 이해가 있으시면 쉽게 이해하실 수 있을 거에요!

옵션을 하나씩 살펴보겠습니다.
◆ DATA : 데이터셋
분석에 사용할 데이터셋을 설정합니다.
◆ NOMCAR : 결측자료 처리
보통 결측치는 삭제하거나 대체하는 경우가 많습니다. 하지만, 복합표본에서의 결측치는 버려지지 않고, 어떠한 처리를 통해 분석에서 사용됩니다. 따라서, nomcar 옵션을 통해 결측치 처리에 관한 설정을 해야합니다.

복합표본 자료분석을 하기 위해서는 3가지 가중치가 필요합니다.
◆ STRATA : 층변수
3가지 가중치 중 분산추정층에 관한 옵션입니다. 아래는 이용지침서의 내용 중 일부이고, "kstrata"를 검색하시면 쉽게 찾으실 수 있습니다. 분석 변수에 따라 분산추정층 변수를 달리 해야한다고 언급하고 있습니다. 상황에 맞춰 설정해주시길 바랍니다.

◆ CLUSTER : 집락 변수
조사구 번호를 의미하는 변수입니다. 깊게 생각하면 머리아픕니다. 이 위치에 넣어주시면 됩니다.

◆ WEIGHT : 가중치 변수 *중요!!*
가중치 변수입니다. 음... 개인적으로는 여기가 가장 복잡합니다. 이용지침서 목차를 보시면 가중치 목차가 있습니다. 위의 두 변수는 비교적 쉽게 설정하실 수 있지만, 가중치 파트는 반드시 읽어보시길 바랍니다!!

가중치 부분을 읽어보시면 아래와 같은 표가 나옵니다. 적절한 가중치를 결정하기 위해서는 저희가 분석하고자 하는 데이터의 연도와 변수가 어떤 변수인지 아셔야합니다. 우선 2018년도 데이터이기 때문에 맨 오른쪽 열에서 가중치를 찾아야하고, 그 다음은 저희가 분석할 변수인 HE_sbp변수가 어느 조사부문에 속하고 있는지 확인해야합니다.

이용지침서의 3번 목차가 원시자료 구성입니다. 이 곳에서 각각의 변수 설명을 확인할 수 있습니다.

저희가 사용할 변수는 검진조사의 하위 그룹인 혈압 측정에 속한 변수임을 확인할 수 있습니다. (위의 목차에서 3번은 영양조사이지만, 이용지침서를 확인해보시면 3-2. 혈압 측정은 검진조사의 하위 부문입니다!) 이제 다시 위의 표를 확인해보면.... 2018년도의 검진조사 기본가중치인 itvex를 사용하면 되는 것을 알 수 있습니다. 실제 데이터에 저장되어 있는 변수명은 wt_itvex입니다.

*가중치 변수는 제가 캡쳐한 것보다 훨씬 디테일한 경우가 많습니다...! 반드시 읽어보시길 바랍니다!
◆ CLASS : 범주형 변수 설정
비교할 집단에 대한 변수를 넣어주시면 됩니다. 현재 상황에서는 성별을 의미하는 sex가 되겠습니다.
◆ MODEL : 회귀식 설정
분석하려는 회귀식을 설정하는 단계입니다. T검정인데 왠 회귀식?? 이라고 생각하실 수도 있는데, 위에서 말씀드렸다시피 Dummy Variable과 회귀분석에 대해 이해하고 계시다면 어느정도 감은 잡으실 수 있습니다. 만약 이해가 안 된다고 하더라도 크게 걱정하지 마세요. 그냥 CLASS에서 지정했던 변수와 평균을 구할 변수를 사용하시면 됩니다. 이 경우에는 HE_sbp = sex 라고 작성하시면 되겠습니다. 그 뒤로 다양한 옵션이 추가되어 있는데, 아래를 참고해주세요.
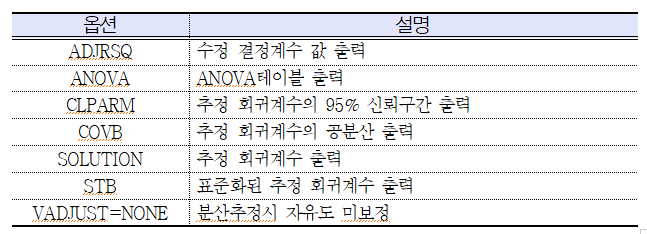
◆ DOMAIN : 관심 집단 변수 설정
처음에 말씀드렸다시피 복합표본 자료 분석에서는 관측치를 삭제하거나 일부만 사용하지 말라고 합니다. 그렇기 때문에 관심 집단을 구분할 수 있는 age30이라는 변수를 만들었습니다. 이 곳에는 관심변수를 나타내는 변수를 입력해주시면 됩니다. 여기서는 age30이 되겠습니다.
여기까지 오시느라 수고많으셨습니다. 완성된 명령문은 아래와 같습니다.

결과 해석
한 번에 결과가 3개가 나타날 겁니다. 각각 맨 위의 표를 캡쳐해왔는데, 이 중에서 우리가 봐야할 결과는 단 하나입니다.



마지막 캡쳐를 보시면 age30=1 이라고 있습니다. 저희가 설정한 관심 집단에 대해 결과가 따로 나오다보니 여러가지 결과를 보여주는 건데요. 저희가 관심있는 집단은 나이가 30이상인, 즉, age30=1인 집단이기 때문에 마지막 결과를 확인해주셔야합니다. 아래는 age30=1인 집단에 대한 결과입니다.

2번째 표에서 Model행을 보시면 P-value가 0.05보다 작으므로 귀무가설을 기각하게 됩니다. 따라서, "만 30세 이상에서 성별에 따른 수축기 혈압의 평균은 차이가 있다"는 해석을 할 수 있습니다. 여기서 sex 1이 남자이고, sex 2가 여자이므로 남자의 수축기 혈압의 평균은 (117.3787 + 3.4094)mmHg, 여자의 수축기 혈압의 평균은 117.3787mmHg이며, 남자가 약 3.4094mmHg 높은 것으로 나타난 것을 확인할 수 있습니다.
최대한 바로바로 써먹을 수 있도록 포스팅을 하다보니.. 사기치는 느낌입니다 ㅋㅋ;;; 쉽게 하려다보니 그런 느낌을 지울 순 없는 것 같네요.. 그렇다고 그리 쉬운 것은 아닌 것 같고..ㅋㅋㅋ... 어쨌든 이것으로 SAS를 이용한 복합표본에서 두 집단의 평균 차이를 검정하는 포스팅을 마치도록 하겠습니다.
이상, 산격동 너구리였습니다.
감사합니다.
* 잘못된 정보 및 오타가 포함되어 있을 수 있습니다.
그대로 받아들이시기보다는 다른 사람의 의견도 참고하셔서 분석하시길 바랍니다.
* 포스팅 내용 및 통계 분석 관련 질문은 언제나 환영입니다.
가능한 선에서 최대한 답변하도록 하겠습니다.
'내가 하는 통계 분석 > SAS' 카테고리의 다른 글
| [내가 하는 통계 분석] 복합표본 평균 차이 검정 (6) | 2021.06.03 |
|---|---|
| [내가 하는 통계 분석] 국민건강영양조사 분석 준비 in SAS (7) | 2021.05.09 |
| [내가 하는 통계 분석] 스피어만 상관 계수(Spearman correlation coefficient), 켄달 타우 계수(Kendall tau coefficient) in SAS (0) | 2021.03.15 |
| [내가 하는 통계 분석] 피어슨 상관 계수(Pearson correlation coefficient) in SAS (0) | 2021.03.15 |
| [내가 하는 통계 분석] 정확 맥니마 검정(exact McNemar test) in SAS (0) | 2021.03.15 |